Extensions of Karger's algorithm
If you prefer videos, check out our ICCV presentation, which covers similar content as this blog post. For more details, see our paper.
Karger’s contraction algorithm is a fast and very famous method for finding global minimum graph cuts. First published in 1993, it helped start a wave of other randomized algorithms for graph cut problems. And while many of these are asymptotically even faster, Karger’s algorithm remains important and fascinating in part because of its extreme simplicity — it’s description wouldn’t even require an entire postcard:
Contract a randomly chosen edge, i.e. merge the two nodes it connects into one node. Repeat until only two nodes are left.
We will discuss Karger’s algorithm in a bit more detail shortly. But first, this simplicity raises a question: can Karger’s algorithm be extended to help with other tasks than the global minimum cut problem it was originally meant to solve? That is the question we aim to answer in our new paper and which this blog post will focus on.
One extension that immediately suggests itself, and which we will discuss first, is that to --mincuts. If you already know what --mincuts are and why we’d want to find them, you can read on; if you’d rather have a brief refresher, there’s one in the expandable box below.
Global mincuts and Karger’s algorithm
Karger’s algorithm doesn’t find --mincuts, it finds global minimum cuts. This means that we want to separate a graph into two parts while minimizing the total weight of edges that need to be cut — all without having seeds and that need to be separated.
The following figure illustrates how Karger’s algorithm works on a simple example graph: we first selects an edge at random, in this case the one between and (in red), and then contract the chosen edge. We then repeat this process until only two nodes are left (on the very right). These nodes define a cut of the original graph into the partitions and .

This works for unweighted graphs and for graphs with positive edge weights (in which case edges are selected for contraction with probability proportional to their weight).
Since Karger’s algorithm uses random contractions, it could of course produce a different result on the same input graph, and in particular a non-minimal cut. But importantly, Karger’s algorithm produces a minimum cut with a reasonably high probability: by running it a polynomial number of times, it becomes very likely that at least one run will find a minimum cut. This is far from obvious: there can be an exponential number of cuts of a graph, so Karger’s algorithm needs a very strong bias towards minimum cuts to achieve its high success probability.
Karger’s algorithm for --mincuts?
We can now come to our first question: can methods similar to Karger’s algorithm be applied to the --mincut problem, rather than the global one?
It’s certainly easy to modify Karger’s algorithm such that it always separates and : we simply never contract an edge that connects and (or nodes that or have been merged into). This will make sure that and are on opposite sides of the final remaining edge that defines the cut.
But unfortunately, we show that a wide class of extensions of Karger’s algorithm cannot find --mincuts efficiently — no matter how clever we are in modifying Karger’s algorithm, there will always be some graphs where the success probability is exponentially low. Expand the box below if you want a few more details and intuition, or see the paper itself for all the gory details.
Karger’s algorithm for seeded segmentation
So far, extending Karger’s algorithm doesn’t look promising. But it turns out that there are useful extension of Karger’s algorithm — we just have to switch problems. Instead of a minimum cut, machine learning often requires a “good” segmentation in a vaguer sense — something that leads to good downstream performance. So that’s what we’ll tackle next.
To keep things simple in this blog post, let’s assume that our segmentation problem has only two classes, fore- and background, and that there is only one seed in each class.1 We’ll continue to call these seeds and and still want to separate them, we just don’t want a minimum cut any longer.
We could find a segmentation of the graph by just running Karger’s algorithm once and taking the cut we get that way. But that’s a bad idea: it’s extremely noisy and the individual cuts that Karger’s algorithm produces are often not good segmentations.
So instead, we sample a lot of cuts and then take their “mean”. Mre precisely: we generate an ensemble of cuts using the variation of Karger’s algorithms that never merges the two seeds. Then for each node , we count how often it ended up on the same side of the cut as and how often on the side. We can define the probability that Karger’s algorithm puts on the side of ; our finite ensemble thus gives us an estimate of this probability.
This is illustrated in the following figure: displayed are six cuts that Karger’s algorithm might produce for different runs on the same graph. is on the red side of the cut, the one belonging to , five out of six times, so we would estimate . In practice, we of course use more than six runs.





This probability is a probabilistic segmentation of the input graph. The following figure illustrates this and compares it to the potential that the random walker algorithm produces:
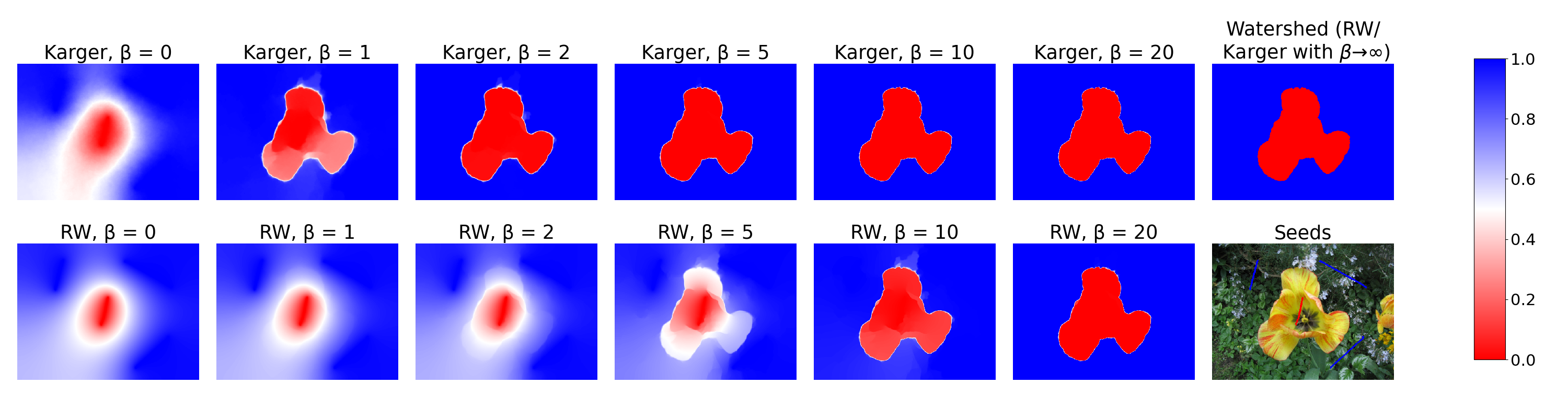
is a parameter that influences how the edge weights are computed based on the image. For large , the edge weights become very extreme and both algorithms assign probabilities close to zero or one to each pixel.
If we need a hard cut, we can simply assign each pixel to the side for which this estimate is higher. This gives an algorithm for seeded graph segmentation. It’s very simple and has a great asymptotic runtime (linear in the number of edges of the graph). We also empirically compared this Karger-based segmentation method to the random walker and other algorithms on image segmentation and semi-supervised classification tasks. In both cases we found that it performs at least as well as these classical algorithms, see the paper for detailed results.
Karger’s algorithm and the random walker
We didn’t compare the Karger-based segmentation algorithm to the random walker just because the latter is one of the most influential algorithms for seeded segmentation of all time: it turns out that these two very different-seeming algorithms are surprisingly similar from a theoretical perspective.
Explaining these similarities takes some setup, so here’s the TL;DR: both algorithms can be interpreted as forest-sampling methods, just sampling from different distributions. The Karger distributions contains an additional dependency on the topology of the graph, which we think makes it more “confident” (i.e. it assigns probabilities closer to zero and one).
If this summary has whetted your appetite, then we encourage you to expand the box below for details.
Conclusion
Karger’s algorithm is a powerful and very influential tool for finding global minimum cuts, so it is natural to ask whether this success can be extended to other important graph problems. We have proven that extending it to the --mincut problem is impossible in a formal sense. However, we did adapt Karger’s algorithm to the problem of seeded graph segmentation, demonstrating its usefulness beyond minimum cuts. In particular, the new algorithm shows that the distribution produced by Karger’s algorithm is itself an interesting subject of study, rather than only the smallest cut found. We have made some steps towards understanding this distribution by linking it to the random walker. But there certainly remains a lot of space to improve our theoretical understanding of the “Karger distribution”, as well as the potential to use it for other purposes than the one we presented.
- Generalizing to many classes and many seeds per class is straightforward, see our paper.↩