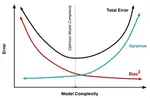
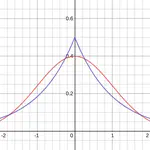
L1 regularization is famous for leading to sparse optima, in contrast to
L2 regularization. There are several ways of understanding this but I’ll
argue that it’s really all about one fact: the L1 norm has a singularity
at the origin, while the L2 norm does not. And this is not just true
for L1 and L2 regularization: singularities are always necessary to get sparse weights.